Just came across this quote in C.J. Date’s Database Design & Relational Theory, which is a more interesting book than the title might suggest.
“In computing, elegance is not a dispensable luxury but a quality that decides between success and failure.
Edsger W. Dijkstra
Watching problems that could have been solved years ago by thoughtful design cascade now one upon the other in the systems at work drives this point home. Spend more time thinking than doing.
As a scholar and open source devotee, Zotero is my life. (Click the link to learn about the best bibliographic management software in the world.) I use it as a personal library, a personal assistant. Sometimes it feels almost like a second brain: the brain where I’ve stored all of the connections between books and ideas that I need to function as a historian so I can focus on other things with the brain in my head.
The only thing it’s missing—and this is HUGE—is a useful mobile client. I’ve tried what’s out there and it just doesn’t work for me. As in, it doesn’t work. Period. So for the past few years I’ve been struggling to use the mobile web client, which is sorta OK, but it is weakest exactly where I need Zotero to be strongest: search.
Rather than continue struggling to operate my second brain, I realized that this is an opportunity. Why not develop my own Zotero client for iPhone and learn Swift along the way?
Consider this, then, the first in a long series of posts documenting the creation of this tool. I have yet to name the project and will begin listing features in future posts. Like Zotero, this will be a truly open source endeavor. I encourage anyone reading this to chime in with ideas or suggestions. If you’d like to volunteer, send me an email or comment below.
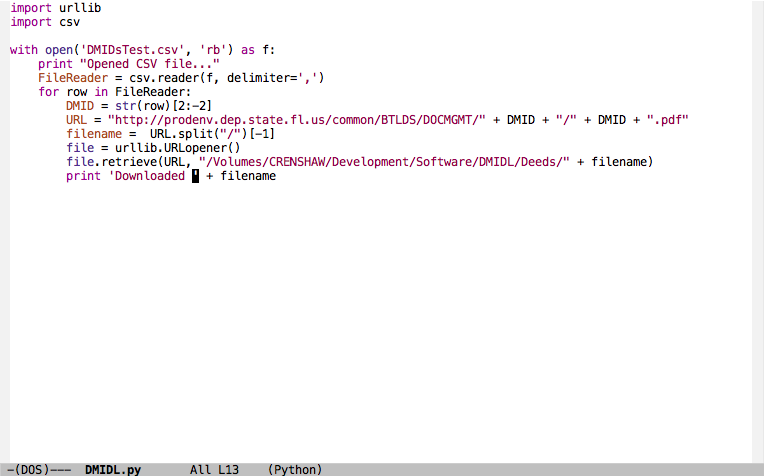
I am not a programmer. I wouldn’t even call myself a coder. But that doesn’t mean I can’t use code to make my life a little easier. Here’s a very simple Python script I wrote yesterday morning that saved me hours of work:
What does it do, and how does it do it?
Let’s start with the problem. In my day job, I work with public real estate. I deal with property deeds. Lots and lots of deeds that are (conveniently) hosted on a web server.
Today I was given a list of more than 220 deeds to download and attach to another document. I could have downloaded each one of them from the server, by hand, but that would have taken several long, tedious hours. Instead, I wrote 13 lines of code that downloaded the deeds in less than five minutes.
Here’s how it works. The first two lines are used to import “libraries.” These are tools that other programmers have created to make everyone else’s life easier by solving common problems. In this case, I imported urllib, which is used to grab resources from URLs (i.e., files on networks, like the web), and csv, which is used to work with CSV files. CSV stands for Comma Separated Value, and is exactly what it sounds like: a list of values separated by commas. In this case, I took the list of deed numbers (or DMIDs, which is an internal identifier used within my state agency) and saved them in Excel as a .csv. Easy!
After importing the libraries, it’s time to work with the CSV file and web resources. The first line opens the csv file, prepares to read it (the ‘rb’ part), and assigns it a name, “f,” which I can use to refer to it later. The next line just tells me that the operation worked by printing “Opened CSV file…” on the screen. The next line after that mostly pointless one uses the csv library I imported earlier to read the CSV file. Again, it is assigned to a variable for ease of use later. Note that there are two variables here: one pointing to the file, “f,” and one pointing to the results of an operation that reads the file, “FileReader.” This operation creates a list of items that would look like this if printed:
[‘345808’]
[‘357121’]
[‘15298’]
After that, we’ll work with the contents of the file row by row—which is why the last line before the indent states “for row in FileReader.” The next line after that “grabs” the DMID from the list and strips away the brackets. The next line attaches the DMID to a string to create the URL of the resource. After that I create the filename for the local system by stripping it from the URL. The next line invokes a function of the url lib library and assigns it to a name; and then the line below that retrieves the URL and saves it to a location on the filesystem—in this case, a file on my flash drive. The program then reports that it downloaded the file before moving onto the next row of the CSV. Everything below the “for row in FileReader” line continues running until it has run out of rows to read. Done.



{kind=link}